교과목 개요
교과목 개요
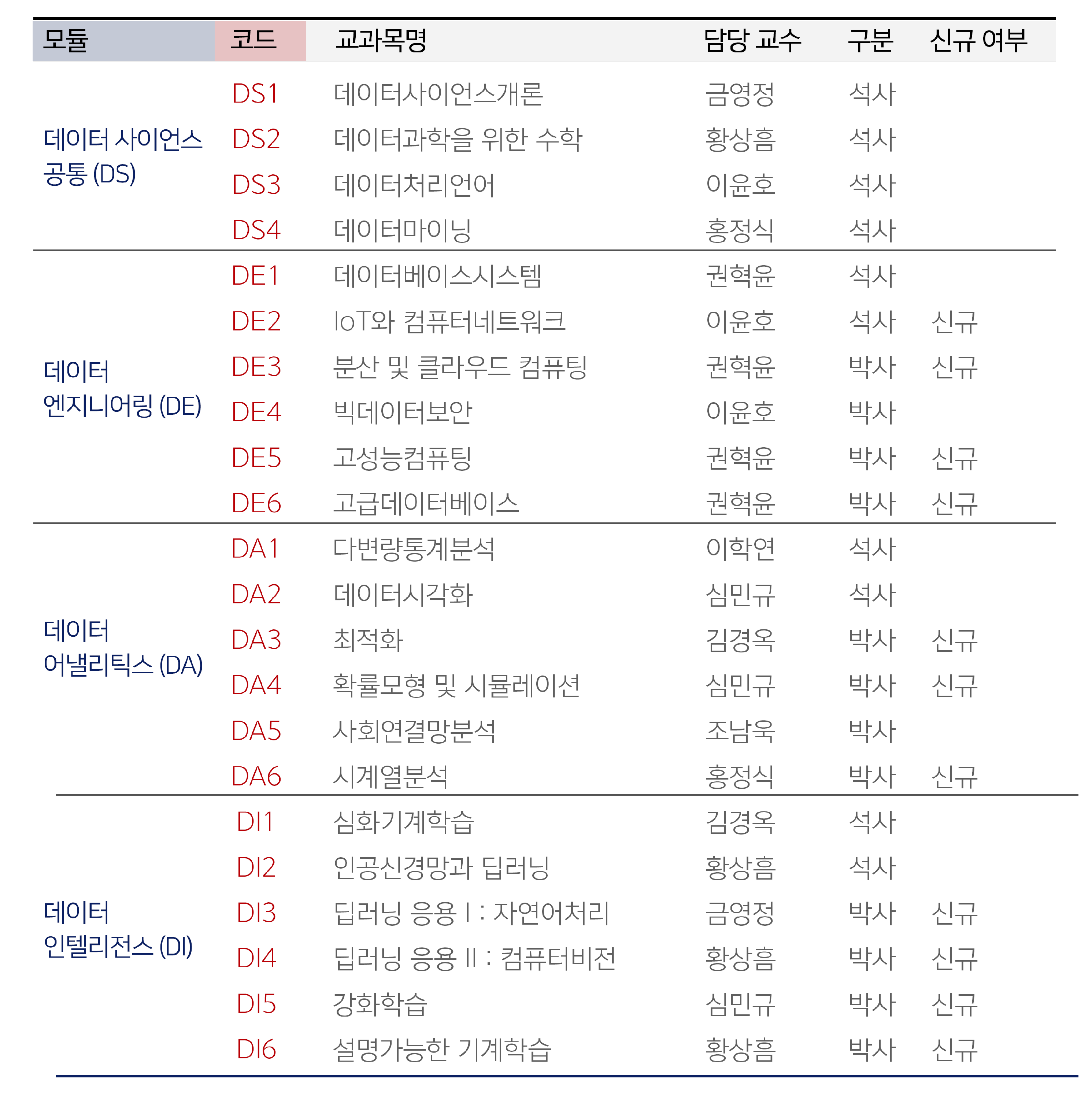
[DS1] 데이터사이언스개론 (Introduction to Data Science)
통계학, 컴퓨터공학, 산업공학, 사회과학 등을 결합한 융합학문인 데이터 사이언스의 개념을 이해하고 데이터 과학자가 갖추어야 할 역량들을 함양하기 위한 학습 로드맵을 제시한다. 또한, 데이터 사이언스의 기초가 되는 기술 및 추론 통계학(Descriptive & Inferential Statistics)의 이론적 학습과 함께 실습을 수행한다.
[DS2] 데이터과학을 위한 수학 (Mathematics for Data Science)
데이터 분석의 도구로 활용되는 데이터마이닝/기계학습 방법론들을 이해하고 활용하기 위한 확률 및 통계, 선형대수, 최적화 관련 기본적인 수학 지식을 학습한다.
[DS3] 데이터처리언어 (Programming Language for Data Analytics)
데이터 사이언스의 주요 분석도구로서 사용될 Python 언어를 학습한다. Python의 기본적인 활용법과 함께 통계 분석에 대한 실습을 수행하고, 이를 바탕으로 텍스트 처리, 웹문서 처리 방법을 학습한다.
[DS4] 데이터마이닝 (Data Mining)
대용량의 데이터로부터 유용한 지식을 탐색/발견하는 데이터마이닝의 기본 개념을 학습하고 분류 및 회귀, 군집화, 연관 규칙 분석, 이상치 탐지 등 데이터마이닝의 주요 방법론에 대한 이론적 이해와 비즈니스 활용 사례를 탐구한다. 또한 Python을 이용하여 데이터마이닝 방법론 구현 및 활용에 대한 실습을 수행한다.
[DE1] 데이터베이스시스템 (Database Systems)
SQL, 트랜잭션 관리, 정규화, 질의 최적화 등 데이터베이스의 고급 기술과 분산 데이터베이스 이론을 학습한다. 실용적인 예제 및 실생활의 문제를 바탕으로 상용 데이터베이스(Oracle)를 이용한 실습을 수행한다.
[DE2] IoT와 컴퓨터네트워크 (IoT and Computer Networks)
네트워크 계층 구조를 이해하고 TCP, UDP, HTTP 등 데이터 교환에 사용되는 다양한 프로토콜을 학습한다. 또한, 다양한 유형의 IoT 디바이스로부터 수집된 결과를 전송하고 관리하기 위한 통신 방법을 학습한다.
[DE3] 분산 및 클라우드 컴퓨팅 (Distributed and Cloud Computing)
Hadoop, MapReduce, NoSQL, NewSQL 등 분산 기반 대용량 데이터 관리 및 처리 기법을 학습한다. 또한, Amazon AWS, Microsoft Azure 등 클라우드 서비스에 대해 이해한다.
[DE4] 빅데이터보안 (Security in Big Data)
빅데이터 환경에서 대량의 데이터 수집 및 분석을 바탕으로 향상되는 삶의 질 이면에 대두되는 보안 관련 이슈를 이해하고 이를 해결하기 위한 기술적인 방법론을 이론적으로 학습하고 실습한다.
[DE5] 고성능컴퓨팅 (High Performance Computing)
최신 HPC(High Performance Computing) 시스템을 이해하고 성능을 최적화하기 위한 메모리 계층 구조를 학습한다. 또한, HPC를 활용하여 최적의 성능을 도출하기 위한 병렬 프로그래밍 기법을 학습한다.
[DE6] 고급데이터베이스 (Advanced Databases)
데이터베이스 및 빅데이터 관리 시스템에서 사용된 주요 기법들에 대한 이론적인 기반과 실제 응용에 대해 학습한다. 구체적으로, 공간 데이터, 텍스트 데이터 등 다양한 유형의 데이터를 효율적으로 저장하고 검색하기 위한 색인 구조, 관계형 데이터베이스 및 NoSQL 데이터베이스의 유형별 이론 및 실제, Transaction 및 Recovery 기법을 다룬다. 또한, 오픈 소스로 공개된 최신 데이터베이스 시스템에 구현된 실제 방법론 및 알고리즘을 이해하고 이를 개선하기 위한 프로젝트를 수행한다.
[DA1] 다변량통계분석 (Multivariate Statistics)
회귀분석, 요인분석 및 군집분석 등 다변량 통계기법에 대한 수리적인 개념의 이해와 R을 활용한 실습을 수행한다.
[DA2] 데이터시각화 (Data Visualization)
빅데이터를 효과적으로 시각화하는 기법을 학습한다. 기본적인 데이터의 시각화 디자인 기법과 평가 방법에 더하여 다변량/텍스트/네트워크 데이터 등 다양한 형태의 데이터를 시각화하는 기법을 R 및 Python 언어를 사용하여 구현 및 검증한다.
[DA3] 최적화 (Optimization)
최적화는 다양한 비즈니스 영역에서 한정된 자원의 효율적 사용, 수익의 극대화를 위한 의사결정 등의 문제를 해결할 때뿐 아니라 기계학습 알고리즘을 이용해 다량의 데이터로부터 최적의 모델을 구축할 때도 필수적이다. 이 과목은 다양한 선형, 비선형 최적화 문제에 적용 가능한 최적화 기법을 이해하고 실제로 적용하는 방법을 학습하는 것을 목표로 한다.
[DA4] 확률모형 및 시뮬레이션 (Stochastic Model and Simulation)
본 과목은 시간에 따라서 값이 변화하는 확률 변수의 모형을 다룬다. 마크브 과정, 프아송 및 재생 과정을 다루고 해당 모델이 적용되는 시스템을 분석하는 기법을 다룬다. 또한 데이터를 컴퓨터를 이용하여 생성하여 추적하고 분석하는 시뮬레이션 기법을 컴퓨터 프로그래밍과 통계학 이론을 바탕으로 구현한다. 산업 현장에 확률 모형을 적용하고 데이터를 생성해 성능을 분석한다.
[DA5] 사회연결망분석 (Social Network Analysis)
사회적 관계(연결망)를 분석하여 사회현상에 담긴 함의를 분석한다. 사회연결망 분석의 이론적 배경, 주요 개념 및 방법, 자료의 수집과 분석 방법 등을 다루고, 연결망분석을 활용한 연구결과를 조사하는 동시에 정해진 주제를 토대로 자료 수집 및 분석 능력을 함양한다.
[DA6] 시계열분석 (Time Series Analysis)
시계열 자료의 기본적인 성질과 시계열 자료의 분석을 위한 개념들을 소개하고, 이를 바탕으로 ARIMA(Auto Regressive Integrated Moving Average) 모형의 모수추정방법을 다룬다. 또한 시계열 자료의 최신 분석 방법인 RNN(Recurrent Neural Network) 모형의 사용 방법을 소개하고 이를 토대로 실제 시계열 자료를 분석해 본다.
[DI1] 심화기계학습 (Advanced Machine Learning)
빅데이터 분석의 핵심 기술로 기계학습의 심화 알고리즘인 Support Vector Machine, Ensemble learning, Graph 기반 모델 등의 이론적 원리를 학습하고 Python을 이용한 알고리즘 구현 및 실제 사례 적용 등의 실습을 수행한다
[DI2] 인공신경망과 딥러닝 (Neural Network and Deep Learning)
인공신경망의 기본 원리와 활용 방법을 학습하고 딥러닝의 발전 과정과 응용 사례들을 알아본다. 또한 공개된 라이브러리를 이용하여 딥러닝 프로젝트를 수행한다.
[DI3] 딥러닝응용I: 자연어처리 (Deep Learning Application I: Natural Language Processing)
순환 신경망, 게이트 순환 신경망, 어텐션 등의 자연어 처리를 위한 최신 딥러닝 모형들을 알아보고, 자연어 처리의 응용 분야들을 학습한다.
[DI4] 딥러닝응용II: 컴퓨터비전 (Deep Learning Application II: Computer Vision)
컴퓨터 비전을 위한 합성곱 신경망 기반의 최신 딥러닝 모형들을 학습하고, 이를 객체 인식, 객체 검출, 영역 검출 등의 다양한 컴퓨터 비전 과제에 적용한다.
[DI5] 강화학습 (Reinforcement Learning)
강화학습은 바둑이나 체스와 같은 보드 게임, 자율 주행 자동차와 같은 무인기기, 금융 거래와 투자의 무인화와 같은 첨단 인공지능 분야이다. 강화학습에서는 환경을 인식하고 목표를 성공적으로 달성하는 주체인 “지능형 에이전트”를 학습한다. 본 과목은 지능형 에이전트가 처한 환경에 해당하는 마코브 의사결정과정의 이론과 응용으로 시작하여 대표적인 강화학습 알고리즘의 이론을 다루고 산업 현장에서 무인 의사결정을 담당하는 지능형 에이전트를 구현한다.
[DI6] 설명가능한 기계학습 (Explainable Machine Learning)
기계학습 모델의 예측을 의사결정에 활용하기 위해서는 그 예측을 설명하고 해석할 수 있어야 한다. 본 교과목에서는 해석 가능성의 개념을 알아보고, 예측의 설명력이 우수한 기계학습 모델들을 소개한다. 나아가 기계학습 모델과 관계없이 적용할 수 있는 일반적인 해석 방법론들을 학습한다.